To avoid taking a year again to (fail to) put my notes together, I decide to do it quickly and stick to a few thoughts and highlights. The 2024 edition of ShipItCon happened today. This year's theme was "Flow." Many speakers mentioned ownership when talking about ways to reach flow.
I haven't attended many conferences in the last couple of years, but maybe 90% of the people I talked to were also meeting their co-workers face-to-face for the first time at this event, despite working together for years. At least three different companies. I found it interesting. It doesn't look like there are many opportunities for teams to meet outside of conferences at the moment.

DevOps Topologies 10 years on: what have we learned about silos, collaboration, and flow? (Matthew Skelton)
The speaker kindly summarised his findings both at the start and the end of the talk: decouple teams and tech (not just defining an org structure, something more dynamic), but diffuse learning across the company (that can take the form of Lunch and Learns, blogs, Communities of Practice, guides, etc...)
Reading recs:
- Gene Kim's books (the Phoenix Project, Accelerate, ...)
- SODOR, the State Of DevOps Reports
Organisation, Flow, and Architecture (Sam Newman)
What an incredibly dynamic and engaging speaker! The theme was generally how to reduce handoffs, which happens particularly when organisation are siloed.
Conway's law: An organisation design systems that replicate the communication structure of that organisation.
So if you have Taylorism-inspired silos with e.g. separate front-end/back-end/DB teams, the system will reproduce that.
The solution is feature-based teams (micro-services are good to enable full ownership). Durable as opposed to initiative-based teams are also better as long-lived teams make better decisions about trade-offs (e.g. incurred tech debt, etc).
Data Driven Decisions to Improve Testing Flows (Heather Reid)
Using data to take risks. Differentiating between reversible and not reversible risks. The speaker used various examples based on her own experiences to illustrate the principle.
For example: closing an old bug to remove noise is easily reversible if it turns out it shouldn't have been closed.
If 1000s of users report a problem, it can feel like millions/all of your users are hitting the problem. But maybe when you look at the data it's 0.6% of the userbase, which is still bad but not world-ending.
Or a really bad bug affecting 6 users using that phone model (out of millions) can probably be closed.
Prioritise accordingly.
Observability 2.0 and other things (Charity Majors)
(The title isn't on the agenda and I forgot to write it down!)
Tip for how to supercharge your career: join a high-performing team.
Engineering should own the code in production.
Observability is a property of complex systems.
Observability-driven development means looking at your dashboards (as opposed to waiting for alerts/paging to bring them up). It's a constant conversation with code (including unstructured logs, not just metrics, because they provide CONTEXT). (Higher level: structured logs with trace ids you can follow end to end.)
Establishing a culture of ownership and observability at Phorest (Paweł Malon and Paul Dailly)
Interestingly, the speakers use Honeycomb which is the observability platform of the previous speaker. It was like seeing practical examples of the concepts detailed in the previous talk.
The theme of engineering owning the code all the way to production came up again.
And also, of linking engineering workflows to observability: deploying a change and seeing what difference it makes, and conversely using the insights gained from observing software behaviour on prod to find new bugs/improvements.
Having a lot of metrics does create issues with the cost of storing all of that data, which is where sampling helps, although the speakers talked about the other problems you then have to deal with when sampling and how to manage them.
Go With The Flow? (Vessy Tasheva)
Play is a component of flow. Venn diagram of Play and Environment with Flow where the circles meet.
Environment: must be safe even if there are constraints/discomfort. E.g. a leader having your back when working on a challenging project.
Play is a way to be more authentic and creative. "Being" (which respects focus time) vs "Reacting" (which breaks flows and creates defensiveness).
Flow-etry in Motion: Navigating Cascades of Threat Data (Claire Burn)
Interesting twist to the talk! When the speaker submitted it, it was supposed to be about how their pivot to using Kubernetes and Google Cloud Platform enabled better flow in the team. But by the time the conference happened, they had reverted back to AWS and EC2!
There was no "peak flow" to be found because Kubernetes wasn't the right tool to solve their problems (they needed finer grained OS control).
Considerations around Learning Curve vs Velocity, especially when working as a smaller team (4 people). The management debt became too much.
They did end up keeping Kotlin from this experiment, good for integration with other Java projects in the company.
The impact of Flow on various aspects of work (Panel discussion)
Beat Saber as a way to get into flow 😂
Distributed teams are good for making the implicit explicit. Managing based on outcomes. The additional flexibility is good for everyone.
Honeycomb has a quarterly "everyone works from home" week, up to the CEO. It's good to get distance from processes, etc. (I thought that was a refreshing contrast to all the Return To Office talk from the last couple of years.)
Many problems are socio-technical: need a combination of tech and people solutions, not just one or the other.
Harnessing Developer Insights to maximise flow (Mihai Paun and Alma Tarfa)
Learned helplessness in companies: "we've always done it this way" "that's never going to work here."
I really liked the picture of the Iceberg of Ignorance, from Corporate Rebels:
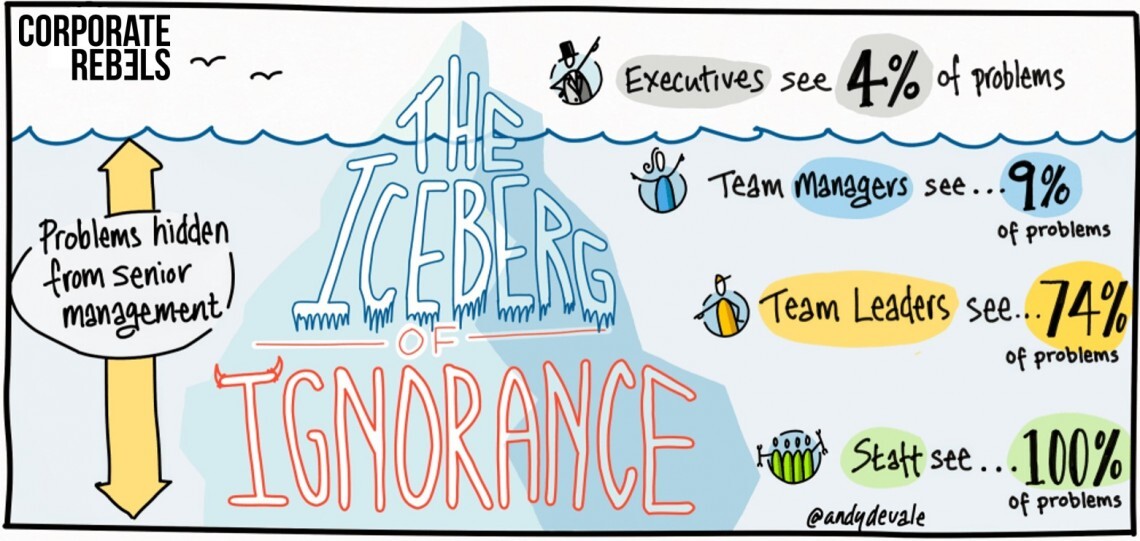
Papercuts affecting flow tend not to surface in retrospectives.
Solution: Plan - Do (gather data) - Check (target condition) - Act
For example, they found their dev team struggled to reach flow state because of the number of meetings, so they decided to try setting up two no-meetings day (Monday, Wednesday) then gather data to see if that helped. Everyone involved in the four steps.
Small changes toward reaching the bigger goal.
Leaders: be gardeners, not mechanics.
From MLOps to AI Systems (Jim Dowling)
Most AI systems don't ship. This hasn't changed in the last few years.
MLOps, LLMOps. He explained when he teaches a ML course, his students complete an AI project from scratch in 2 weeks. It doesn't need to be as complicated as 30+ steps diagrams/consultants make it out to be.
While looking for a link to the course, I came across this detailed article that goes into the details of the talk if that is of interest. And includes a link to the students' projects.
Finding personal flow (Patrick Kua)
Personal flow usually comes from:
- adding value
- learning
- having a lot of ownership (with support)
- a sense of progress
- applying the team's strengths
The speaker used past experiences to illustrate various kind of very different environments that can lead to good flow. This actually linked back nicely to Vessy's earlier talk as well: challenging projects but in a safe environment/with support.
One of the anecdotes I liked was when he was trying to remove himself as a bottleneck in a large project, he broke down the features, and asked if anyone would step up as feature leads for each of those. People had no problem volunteering and that also links back to ownership again. And feature-based teams.
The disadvantage of putting up notes early is that the recordings are not yet available!